

Learn More
Pricing
With the deep penetration of financial technology, business systems in financial fields such as securities, investment banks, and commercial banks have shown the dual characteristics of "surge in complexity + accelerated delivery". Zhongtai Securities data shows that the iteration cycle of the core business system in the securities industry has been compressed from "monthly level" to "weekly level".
The traditional testing model faces bottlenecks such as:
- Low efficiency in use case writing (manual writing accounts for more than 70%)
- Difficulty in knowledge inheritance (reliance on expert experience)
- Lagging security detection (the missed detection rate of code vulnerabilities exceeds 30%)
Against this background, AI test assistants with large models as the core have become the key to breaking the situation. Through the two-layer architecture of "technical base + scene empowerment", they realize the transition of testing from "artificial drive" to "intelligent drive". Financial systems have high complexity, strong supervision and zero fault tolerance requirements, and testing requirements emphasize compliance verification, risk coverage and rapid iteration. Large model-driven AI testing assistants have been rapidly implemented in the financial field and have become the key to reconstructing the quality assurance system.

The AI testing assistant driven by Large Language Models (LLMs) marks the transition of software testing from traditional automation to an intelligent paradigm. Its technical architecture evolution has the following stages:
- Core reliance: Script recording/playback and rule drive of tools such as Selenium
- Pain points: High script maintenance costs, UI changes easily leading to failures, insufficient understanding of complex businesses
- Core capability: Introducing machine learning algorithms to achieve defect prediction, test prioritization and log analysis
- Limitations: Requires a large amount of annotated data, limited generalization capabilities, inability to handle unstructured needs
- Core engine: LLMs (such as GPT and Llama series)
- Typical architectural features:
- Core components: LLM basic model + RAG (Retrieval-Augmented Generation) knowledge base + Agent framework (planning-execution-feedback loop)
- Interaction process: Preparation phase (Prompt engineering, context construction) → Interaction phase (multiple rounds of reasoning, tool invocation) → Verification phase (illusion detection, execution feedback)
- Key capabilities: Multi-modal perception (processing UI, logs, code), intent recognition, dynamic learning and adaptive script generation
- Evolution trend: From single LLM assistant to multi-Agent collaboration; combining fine-tuning and hybrid tool integration to improve domain adaptability
Research shows that LLMs perform well in unit test generation, advanced scenario testing, assertion generation and non-functional testing (such as security/usability), but need to solve challenges such as prompt sensitivity, hallucination and inconsistent evaluation indicators.
The core of the large model-driven AI test assistant lies in building a technical system of "layered decoupling and capability reuse". The practices of Zhongtai Securities, Suzhou Bank and other institutions have formed a standardized architecture paradigm:
- Deployment mode: Dual support for privatized deployment and SaaS access
- Technical support: Rely on GPU cluster and virtualization technology, support CPU/GPU elastic scheduling
- Case practice: Zhongtai Securities uses privatized deployment of open source models such as Tongyi Qianwen and DeepSeek to ensure sensitive data does not leave the domain; single model inference speed is increased by more than 3 times
- Core goal: Solve the "illusion" and domain adaptation problems of large models
- Agent framework: Realize Workflow orchestration (e.g., "requirement analysis → use case generation → result verification" automated process); CITIC Bank shortens test script generation time by 50%
- RAG knowledge base: Build vertical domain knowledge base through document slicing and vectorization processing; Suzhou Bank increases test case generation accuracy to 81% and reduces hallucination rate by 40%
- Core functions: Encapsulate intent recognition, multi-round dialogue, function calling, etc.
- Case practice:
- Zhongtai Securities: Automatically parse interface documents, extract request parameters and response structures, generate scripts executable by Postman/JMeter
- Suzhou Bank: Realize closed loop of "atomized demand splitting → test point generation → use case output", shorten single demand use case generation time from 2 hours to 10 minutes
- Core scenario directions:
- Test case generation (covering function/interface/UI testing)
- Test knowledge Q&A (such as compliance clause query, test specification interpretation)
- Code security detection (identifying SQL injection, XSS and other vulnerabilities)
- Effect: Improves test case design efficiency by 1.5 times and increases code vulnerability detection rate by 25% (Zhongtai Securities practice)
- Core positioning: "Privatized deployment + domain adaptation" to solve "data sensitivity + business complexity" pain points
- Technology implementation:
- Basic layer: GPU cluster privatized deployment + data desensitization gateway
- Component layer: Agent process orchestration + securities vertical knowledge base (100,000+ use cases, 2,000+ business rule documents)
- Application layer: Three-level prompt word strategy to solve token restrictions and understanding deviations (use case accuracy rate 92%)
- Core scenario effects:
- Interface test: Regression test time compressed from 12 hours to 4.8 hours (efficiency increased by 60%)
- Code security detection: High-risk vulnerability location accuracy exceeds 90%, manual review time reduced by 80%
- Performance data:
- Interface use case generation efficiency: 20/day → 150/day
- Test data preparation time shortened by 81.25%
- High-risk vulnerability detection rate: 72% → 92%
- Core positioning: "Domain fine-tuning + tool integration" to adapt to small test teams and limited computing power
- Technology implementation:
- Model optimization: Qwen7B-based credit domain fine-tuning, LoRA technology reduces training costs by 90%; INT8 quantification compresses model volume to 7GB
- Deployment mode: API plug-in embedded into JIRA platform, supported by ordinary X86 servers (single use case generation within 1.2 seconds)
- Core scenario effects:
- Credit business testing: 12 types of scenario use cases automatically generated, coverage increased from 65% to 95% (efficiency increased by 8 times)
- Demand document parsing: Parsing time shortened from 48 hours to 1 hour, omission rate reduced to 7%
- Performance data:
- Credit use case generation efficiency: 15/day → 80/day
- Demand analysis efficiency increased by 97.9%
- Low-cost deployment: Cloud GPU instances (500 yuan/day), zero additional cost for plug-in integration
- Core solution: Integrate LLMs with Knowledge Graph, build knowledge graph based on abstract syntax tree (AST)
- Application scenario: Generate accurate unit test cases for complex payment scenarios (multi-currency settlement, risk control rules)
- Result: Significantly improved code quality and developer productivity, included as an LLMOps case by ZenML
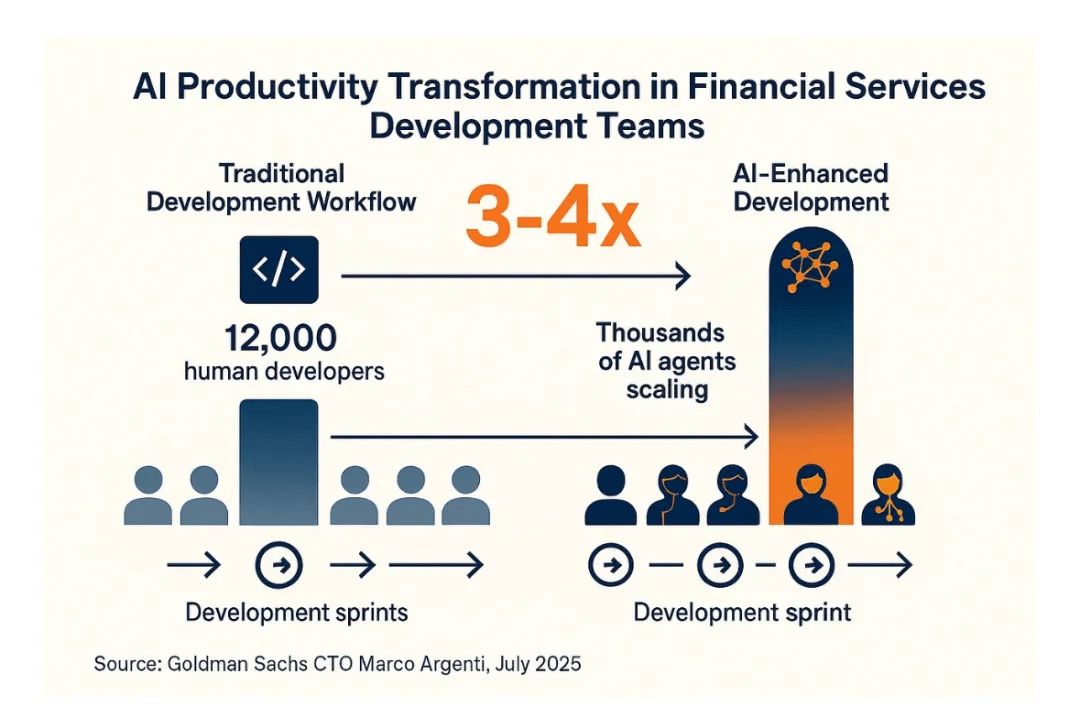
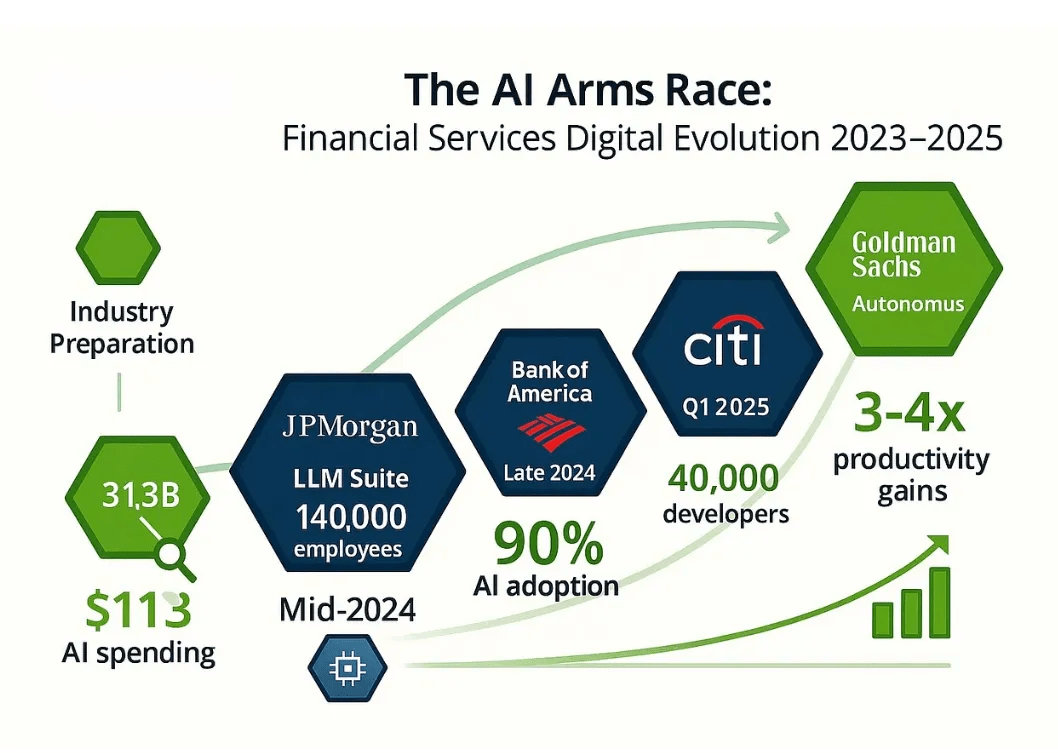
- Core platform: Enterprise-level GenAI platform (GSAI) deployed to 12,000 developers
- Application scenario: Automated unit/integration test generation, self-healing scripts, performance testing; multi-agent collaboration
- Result: Developer productivity increased by 3 times, software delivery accelerated; full-staff GenAI assistant launched in 2025
- Core tool: IBM watsonx Code Assistant, agentic AI tools
- Application scenario: Legacy COBOL code migration to Java, automated test generation/verification/refactoring
- Result: Accelerated mainframe modernization, reduced manual testing workload; full deployment of agent AI in 2023
- Core platform: LLMSuite (integrated OpenAI/Anthropic model, updated every 8 weeks)
- Application scenario: Fraud detection testing, risk management automated testing, performance evaluation and regression testing
- Result: Reduced fraud losses, accelerated software delivery; won 2025 Innovation Award
2026 Key Trends
1. Multi-modal deep integration: Combine visual recognition (UI control recognition) and speech-to-text (test log analysis) to expand UI automated testing, voice interaction system testing, etc.
2. Tool chain seamless integration: Collaborate with DevOps platforms (Jenkins) and test management tools (JIRA) to realize full-link data connection of "requirements → testing → defects"
3. Technological evolution: GenAI independently writes complex scripts, combines quantum simulation to improve coverage; multi-agent systems integrate with supervisory AI to form "AI native" development-test pipeline
Industry Challenges to Be Solved
- Model illusion leading to invalid use cases
- Data privacy and compliance risks (financial sensitive data)
- Higher requirements for legacy system compatibility and regulatory interpretability
- Prompt engineering relying on manual experience
- High computing power costs
Case Sources
- Zhongtai Securities: https://mp.weixin.qq.com/s/VhpqEa_6iqq8ImKDL009pw
- Suzhou Bank: https://mp.weixin.qq.com/s/cu2B1kURb7r_pWpXttzbaA
- Adyen: https://www.zenml.io/llmops-database/augmented-unit-test-generation-using-llms
- JPMorgan Chase: https://www.jpmorganchase.com/about/technology/news/omni-ai
- Goldman Sachs: https://lucidate.substack.com/p/goldman-sachs-scales-ai-coding
Source: TesterHome Community