

Precision Testing in Practice: A Fund Team's Journey from Experience-Based to Data-Driven Quality Assurance
Learning Hub 2026-03-17 11:54 274
Learn how Shenwanhongyuan Securities implemented precision testing to reduce regression testing by 67%. This technical guide covers JaCoCo implementation, method-level code mapping, and intelligent test case recommendation for financial services applications.
I. Introduction
Precision testing is a comprehensive computer-aided test analysis system. Its core components include software coverage analysis, bidirectional traceability between test cases and code, intelligent regression test case selection, defect localization, test case clustering analysis, and automated test case generation—these functionalities collectively form a complete precision testing technology system.
At our company (Shenwanhongyuan Securities Co., Ltd.), testing for financial securities business products has primarily relied on manual black-box methods. In actual testing processes, we have faced challenges including the lack of precise testing guidance and test quality measurement, unclear regression testing scope, and inefficient test case management. Therefore, our company decided to implement precision testing to establish a bridge between manual black-box testing and white-box code, transitioning from experience-based methods to technical approaches, thereby improving testing efficiency and quality.
II. Business Scenario Analysis and Problem Identification
2.1 Fund Service Architecture
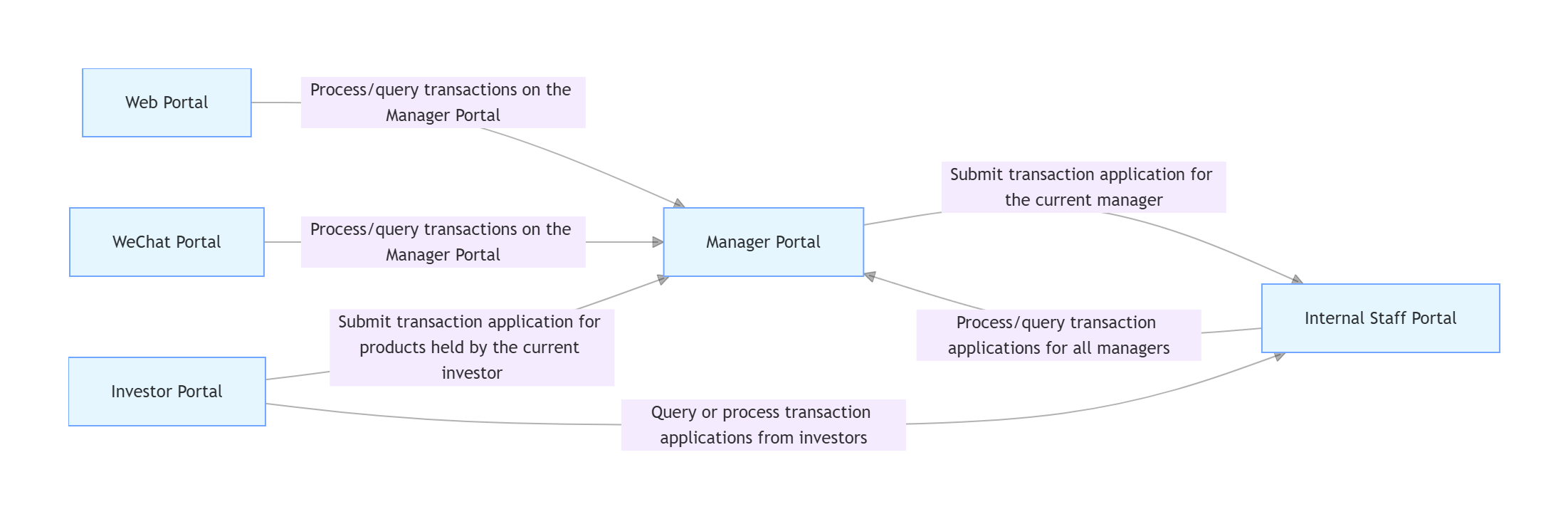
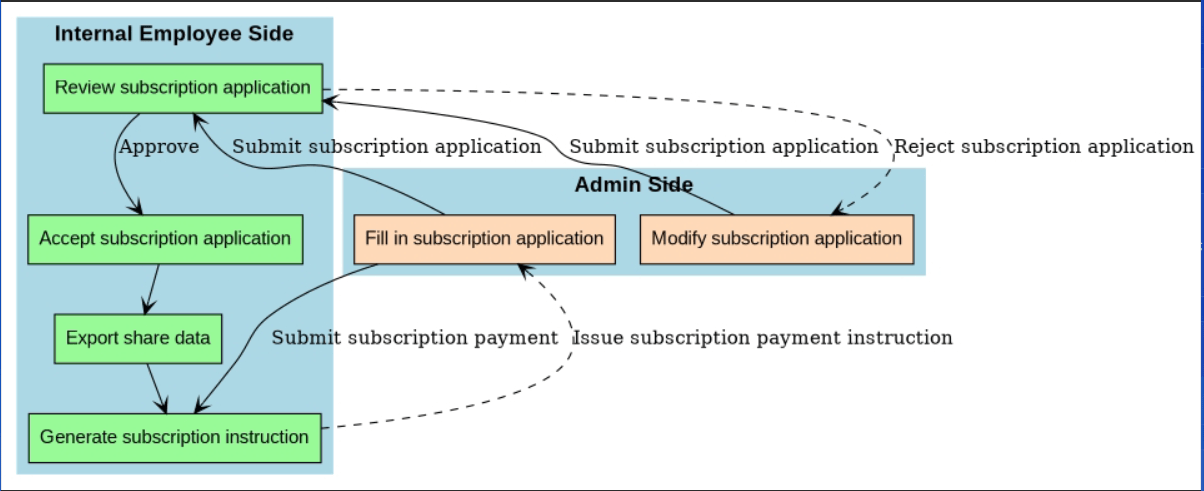
Our company's fund project uses Java as its primary development language, built on the SSM architecture (Spring + SpringMVC + MyBatis). The project consists of multiple modules and components, primarily including six modules: internal employee portal, manager portal, investor portal, website portal, WeChat portal, and interface services. There is extensive business logic and interaction between modules, with one key interaction illustrated in Figure 1. Moreover, this project is process-intensive, with complex process structures and numerous execution path branches. Figure 2 shows the critical interaction flowchart between the manager portal and internal employee portal in product subscription services—modifying certain permissions can lead to different variations in this process.
In summary, during the testing phase, the testing team must ensure that each module and component functions correctly and maintains good interoperability, strictly guaranteeing that every process and branch operates properly. Consequently, code coverage requirements are high. Currently, testing for this project primarily involves manual black-box testing, supplemented by some interface automation and UI automation test cases. Testing scope can only be planned based on manual experience, making it difficult to cover all possible processes and branch scenarios, and impossible to ensure the project's high code coverage requirements are met. Therefore, our company plans to introduce precision testing to address this issue.
[Figure 1: Fund Project Module Interaction Diagram]
[Figure 2: Interaction Flowchart Between Manager Portal and Internal Employee Portal]
2.2 Testing Process Analysis
Through our investigation of the testing process and discussions with the testing team, we mapped out the current testing process of our company's fund team, as shown in Figure 3. Through in-depth communication and careful analysis with the testing team, we identified and collected issues existing in the current testing process, as presented in Table 1.
[Figure 3: Fund Team's Current Testing Process]
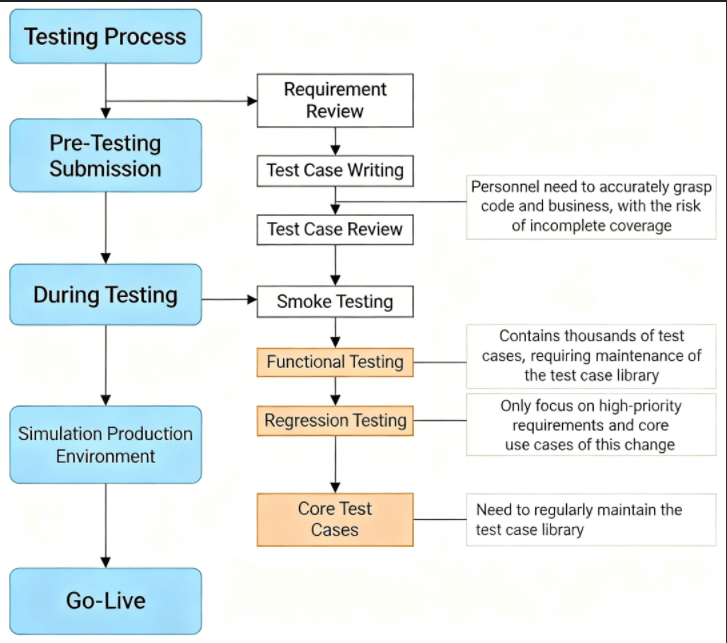
Table 1: Issues in the Current Testing Process
|
Issue No. |
Problem Description |
|---|---|
|
1 |
Primarily black-box functional testing, with testing focus heavily dependent on subjective experience |
|
2 |
Testers lack objective judgment regarding the complexity of requirements submitted for testing |
|
3 |
Testers lack precise judgment when assessing the impact of submitted requirements on existing functionality |
|
4 |
Regression testing only covers newly added cases, neglecting existing ones, creating risk of missing tests |
|
5 |
Full regression testing requires enormous manual and time costs |
|
6 |
Existing case library exceeds 1,000 cases, with cases being redundant or outdated |
|
7 |
Need to identify and streamline the core test case library |
|
8 |
Judgment of core cases relies on manual experience, lacking more efficient evaluation methods |
2.3 Pain Point Analysis
Through thorough discussion, analysis, and summary with the testing team, we categorized the issues from Table 1 into three main areas:
1. Lack of Testing Guidance
As applications expand with business development, the code complexity of various applications continuously increases. How can testers accurately and comprehensively determine the impact scope of code modifications becomes increasingly important; code changes may cause significant alterations to interface logic, requiring testers to evaluate these changes' impact on upper-layer applications; rapid business iterations continuously compress testing time, forcing testers to rely solely on their understanding of code and business, along with personal experience, to delineate testing scope corresponding to requirements. Before testing begins, testers urgently need clear testing guidance to address and optimize these issues.
Such testing guidance should include the following aspects: first, the impact scope of this code modification, including file, class, method, and line levels, to help testers understand the modification's impact scope comprehensively and precisely; second, recommendations of test cases related to the code modification's impact scope, to help testers conduct accurate targeted testing. In summary, through precise data providing professional testing guidance, testers will be able to work more efficiently in agile development mode.
2. Regression Test Case Recommendation
In the regression testing phase, since full regression testing consumes excessive manual and time costs, testers typically can only focus on requirements changed in this iteration and core cases for regression testing. Currently, our company's testers can only determine regression test cases based on their understanding of code and business, which imposes extremely high requirements on testers and carries the risk of missing tests—if misjudgment leads to system issues, it could bring significant losses to the company. Therefore, during regression testing, testers urgently need test case collections related to this code modification for precise, targeted regression testing.
We can recommend corresponding test case collections for regression testing through the impact scope of code modifications. With limited testing resources, this approach allows us to streamline cases, narrow the regression testing scope, effectively detect and verify whether this code modification impacts the system, reduce regression testing time and workload while ensuring low risk of missing tests, and improve testing efficiency.
3. Test Case Management and Maintenance
Throughout the testing process, testers must effectively manage and maintain the test case library. During functional testing, our company's fund business has accumulated thousands of functional test cases, inevitably including some outdated, low-quality, infrequently used, and redundantly covering cases—we need to manage and maintain the functional test case library; before releases, our company executes core cases in production-like environments, and the core case library also requires regular cleanup of invalid cases and addition of new cases. Therefore, we need to provide some new methods for efficiently managing and maintaining the test case library.
Regarding test case library management and maintenance, we can record and provide recommendation frequency and code coverage reports for each test case, helping testers efficiently manage and maintain the case library.
2.4 Technology Selection
Through the above sorting and analysis, our company decided to implement precision testing to establish a bridge between manual black-box testing and white-box code, improving testing efficiency and quality.
The core of precision testing is code coverage collection. In the testing field, code coverage is a key indicator used to measure the extent to which test cases cover source code during testing, evaluate testing breadth and depth, determine whether test cases are sufficiently comprehensive, thereby improving testing quality and accuracy. Different programming languages correspond to different code coverage tools—for example, C/C++ uses GNU Gcov, LLVM/Clang's Code Coverage, BullseyeCoverage, Intel Compiler's Code Coverage, etc.; Java uses JaCoCo, Cobertura, EMMA, etc. Among these, JaCoCo supports rich coverage metrics, provides comprehensive report generation and visualization capabilities, has open-source community support, and offers tight integration capabilities with mainstream build tools. Since our company's fund service uses Java as its primary development language, our precision testing plans to use JaCoCo for code coverage testing.
III. Technical Implementation Analysis
Precision testing can be applied to multiple scenarios, such as intelligent test case recommendation, incremental code coverage evaluation, and test case library maintenance. The most typical and core application scenario is intelligent test case recommendation. Intelligent test case recommendation means we can precisely recommend relevant regression test cases through code changes, making the case set streamlined and more targeted, significantly improving regression testing efficiency and quality. Therefore, our company first conducted application practice of the intelligent test case recommendation system within the fund team, and we will analyze its key technologies in detail below.
3.1 Technical Implementation Process
In the intelligent test case recommendation system, intelligent recommendation for test cases can be achieved through the following steps: first, record test cases to generate code coverage files; next, parse code coverage files and store the mapping between test cases and covered function sets in the database; then, obtain the difference functions between two branches in the project code repository; finally, based on the difference functions, recommend related test cases.
Combined with our company's fund project's actual situation, we summarized the technical implementation process of our case recommendation system, mainly divided into four processes: test case recording, code coverage parsing, code difference parsing, and test case recommendation.
3.2 Code Coverage Parsing
This step is the second process in the case recommendation system's technical implementation flow, primarily using the org.jacoco toolkit, i.e., the JaCoCo API. Figure 5 shows the flowchart for this step. First, prepare the code coverage file (.exec file), bytecode files (downloaded from the test server), and source code files. Then, create an Analyzer object to analyze bytecode files and .exec files, storing analysis results in a CoverageBuilder object. Next, traverse CoverageBuilder to obtain the covered class collection, traverse the covered class collection IClassCoverage to obtain the covered method collection. Finally, store the test case ID and covered method collection in the database.
JaCoCo treats constructors and static initializers as methods, but we don't need to pay attention to their coverage and can filter them out. Method overloading may exist in the project, so we need to obtain method parameters to distinguish them. Here, we introduced the JavaParser toolkit to obtain method parameters (specific principles are detailed in section 3.3): after parsing bytecode to obtain covered classes, find the source file (.java) corresponding to the covered class and convert it to an Abstract Syntax Tree (AST), obtain all methods in the class, and if a method is covered, obtain its method parameters. If errors occur during source file to AST conversion, it may be because the class contains inner classes and the inner class is covered. For example, if class A contains inner class B, compilation generates a bytecode file named A$B—if A$B is covered, looking for A$B.java based on A$B will error, as A$B should correspond to A.java file.
3.3 Code Difference Parsing
After parsing and storing the mapping relationship between each test case and its covered function set, we need to parse code differences between two branches of the project code repository to obtain difference functions. In the code difference parsing step, we primarily used the org.eclipse.jgit and com.github.javaparser toolkits. Figure 6 shows the flowchart for this step.
First, we primarily used the JGit toolkit to obtain difference classes. Using classes and interfaces in the org.eclipse.jgit.api package, we can interact with Git repositories through API methods, cloning the code repositories of two specified branches to the local code repository. Using classes and interfaces in the org.eclipse.jgit.revwalk and org.eclipse.jgit.treewalk packages, we can obtain Git objects corresponding to the two branches, convert repository objects to tree objects, and parse them. Using the org.eclipse.jgit.api.Git and org.eclipse.jgit.api.DiffCommand classes, we can obtain difference classes from the two parsed tree objects; using the org.eclipse.jgit.diff.DiffFormatter class, we can extract detailed information about difference classes (including changed lines).
Then, we used the JavaParser toolkit to obtain difference methods. Using the com.github.javaparser.JavaParser class, we parsed all methods of new and old classes, excluding all methods from interface classes. We customized a MethodVisitor class inheriting from the VoidVisitorAdapter class in the com.github.javaparser.ast.visitor package, overriding its visit() method. In the visit() method, we calculated the MD5 value for each method and obtained method parameters. If MD5 values differ, indicating differences between the two methods, we obtained difference methods by comparing the MD5 values of each method in new and old classes. It should be noted that when MD5 values are used to determine whether two methods are identical, subtle differences such as comments (single-line, multi-line, documentation comments) and blank lines may be calculated as changes—however, in our expectations, these differences should not be judged as changes, so we need to minimize these differences. For comments, we can use the com.github.javaparser.ast.comments toolkit to remove comments.
IV. Considerations During Implementation Practice
4.1 Key Issues and Solutions
During our company's practice of implementing the intelligent test case recommendation system, we encountered some problems. We have sorted and summarized the key issues and their solutions in Table 2.
Table 2: Key Issues and Solutions During Implementation Practice
|
No. |
Process |
Scenario Description |
Considerations and Solutions |
|---|---|---|---|
|
1 |
Case Recording |
JaCoCo instrumentation unsuccessful |
Fill in test server IP for javaagent parameters, plan ports to avoid duplication |
|
2 |
Case Recording |
Dumped code coverage inaccurate |
Ensure no other personnel are using the test server environment during case recording to prevent interference |
|
3 |
Case Recording |
When recording test cases one by one, need to clear test coverage information after each dump to isolate two dumps |
Add parameter --reset to the dump command to clear test coverage information from the machine after completing this dump |
|
4 |
Case Recording |
During interface automation testing, some steps fail |
Failed steps produce incomplete test coverage information—first dump --reset to clear test execution information, then re-execute the test case, re-dump |
|
5 |
Case Recording |
After recording completion, need to cancel instrumentation, revert catalina.sh settings, but process still carries javaagent parameters |
Possibly tomcat process didn't kill when executing shutdown.sh—can use kill -15 to kill |
|
6 |
Code Coverage Parsing |
Reading source code fails |
Check if project directory is standardized—verify if directory is src/main/java/com |
|
7 |
Code Coverage Parsing |
Bytecode and source code do not completely match, causing inaccurate coverage data |
Ensure bytecode and source code version branches match; different compilation environments may produce different bytecode—best to download bytecode directly from test server |
|
8 |
Code Coverage Parsing |
Method overloading exists, need to obtain method parameters for further differentiation |
Use JavaParser to obtain method parameters |
|
9 |
Code Coverage Parsing |
When obtaining method parameters, bytecode has an extra A$B.class, cannot find corresponding A$B.java |
In Java, if a class A contains inner class B, A$B.class is additionally generated to properly load and access inner classes. Trace A$B.class back to A.java file to obtain method parameters |
|
10 |
Code Coverage Parsing |
Need to verify parsed covered function set is correct |
Use JaCoCo API in Java program to generate code coverage report |
|
11 |
Code Coverage Parsing |
Need to filter out some unmonitored methods during parsing |
Exclude some unmonitored methods, such as constructors and static initializers |
|
12 |
Code Difference Parsing |
Method overloading may exist, need to obtain method parameters for further differentiation |
Use JavaParser to obtain method parameters |
|
13 |
Code Difference Parsing |
Using MD5 values to determine whether two functions are identical may cause misjudgment |
Addition/modification of blank lines, comments, spaces do not count as valid differences—can remove comments and format code before calculating MD5 |
|
14 |
Test Case Recommendation |
Some functions have no recommended cases |
Possibly because new/modified requirements lead to code additions/modifications, and new test cases have not yet been recorded; or case library is insufficiently comprehensive |
4.2 Analysis of Mapping Between Cases and Different Granularity Code
During code coverage parsing, using the JaCoCo API can directly obtain code coverage at six levels: class, method, line, instruction, branch, and complexity. During code difference parsing, using Git tools can directly obtain differences at class and line levels—combined with JavaParser, method-level differences can be parsed. Below, we conduct comparative analysis of mapping between test cases and different granularity code from four levels: module, class, method, and line.
4.2.1 Module Level
The module level refers to different functional modules or subsystems within the project. Each module includes classes corresponding to specific functionalities/requirements, with the coarsest granularity. Module-level mapping is suitable for projects with modular structure, requiring clear functional isolation between modules, with each module having its own test case collection. In terms of engineering implementation, code coverage parsing requires additional determination of which module covered classes belong to, then storing the mapping relationship between test cases and modules, consuming minimal storage space; during difference code analysis, additional determination of module attribution for difference classes is similarly required to obtain difference modules.
For our company's fund project, if wanting to perform code mapping from the module level, manual project modularization is first needed—dividing project modules according to functionality/requirements, delineating which classes each module contains. However, due to the complex and numerous interactions between various endpoints in our company's fund project, with dense processes, the manual division and maintenance costs for module scope and module test case collections based on functionality/requirements are relatively high, hence this level is not adopted. Additionally, if changed code involves multiple modules, the recommended test case collection would also be very large, failing to achieve our goal of streamlining regression test cases.
4.2.2 Class Level
The class level refers to each Java class in the project, with relatively coarse granularity. Through mapping analysis between test cases and class-level code, we can perform case recommendation for each difference class. Engineering implementation is relatively simple—during code coverage parsing, project name and covered class information can be directly obtained and stored, consuming minimal storage space; during difference code analysis, difference classes can be directly obtained.
Our company's project is relatively complex—if only mapping to class level, the granularity is too coarse to precisely locate changes, leading to excessive recommended cases. For example, class S contains five methods a, b, c, d, e, mapping to five test cases case1, case2, case3, case4, case5 respectively. When only method c in class A changes, the most reasonable approach is to recommend only case3 corresponding to method c, but class-level mapping would recommend all five test cases corresponding to class A, including invalid case recommendations. Through practice, we found that class-level code mapping sometimes recommends over 80% of test cases, failing to achieve our goal of streamlining regression test cases, hence this level is not adopted.
4.2.3 Method Level
The method level refers to each Java method, with relatively fine granularity, suitable for introducing method call chain analysis. During difference code analysis, we can combine method call chain analysis to locate upstream and downstream influence domains of difference methods, more comprehensively assessing the impact scope of code changes, increasing case recommendation precision. In terms of engineering implementation, code coverage parsing requires obtaining method parameters through JavaParser, storing information about project name, class name, function name (including parameters), with moderate storage space consumption; during difference code analysis, difference functions need to be determined through MD5, and method parameters need to be obtained through JavaParser.
Changes/additions to a requirement in our company's fund project often affect method-level code changes, so method-level mapping is sufficient to achieve precise change location goals. Through practice, we proved the feasibility of engineering implementation, finding the number of recommended test cases to be quite reasonable, capable of streamlining to 15–20% of original regression cases, achieving our goal of streamlining regression test cases.
4.2.4 Line Level
The line level refers to each line of code in each source code file, with too fine granularity. In terms of engineering implementation, code coverage parsing requires storing information about project name, class name, line number, with relatively large storage space consumption; during difference code analysis, information about difference classes and difference lines can be directly obtained.
For our company's fund project, line-level granularity is too fine. As test case numbers continuously increase, storage space consumption grows increasingly large, with gradually apparent query speed limitations, degrading system performance; when analyzing case recommendation results, manual analysis is needed to trace back from difference line numbers to their attributed difference functions, which is inefficient, hence this level is not adopted.
V. Improved Process Design Based on Precision Testing
5.1 Improved Testing Process
Figure 7 shows our company's fund team testing process after introducing precision testing. Through precision testing, via case recording and code coverage parsing, we established a case knowledge base. At the beginning of testing, code difference parsing is performed, generating a code difference document, helping testers understand the impact scope of code changes, changing the current situation where testers relied on personal experience to determine change scope. During regression testing, combining code difference parsing results and the case knowledge base for test case recommendation generates a case recommendation report—conducting precise regression according to the de-duplicated recommended case collection reduces testing costs and improves testing efficiency and quality.
Below, we present our company's precision testing practice results. The code difference document produced by precision practice is shown in Figure 8, and the case recommendation report is shown in Figure 9. Our case recommendation report includes basic information about project branches and the case knowledge base, number of changed functions, number of recommended cases, recommended case collection and recommendation frequency, recommended case details, and other information. This iteration had 50 difference functions, among which 4 functions had recommended cases—indicating these functions successfully mapped to test cases; 46 functions had no recommended cases—indicating the case knowledge base lacked test cases related to these functions. Through in-depth analysis, we found that 41 functions related to newly added methods (newly added functions or functions calling newly added functions), with their test cases also newly added—so we need not pay attention to their recommendation status; the remaining 5 functions unrelated to newly added functions existed in the previous version, but we hadn't recorded test cases related to them, hence no recommendations—this indicates insufficient breadth of our test case scope. In summary, we need to expand the scope of case recording, and the regression test case collection should be the union of recommended test cases and newly added test cases.
[Figure 7: Improved Testing Process]
[Figure 8: Code Difference Document]
[Figure 9: Case Recommendation Report]
5.2 Future Prospects
Currently, our company has successfully implemented the most typical and core application scenario of precision testing—intelligent case recommendation. Based on the intelligent case recommendation system, we can further expand and optimize—for example, optimizing the case recording phase from semi-automated operations to automated recording; adding method call chain analysis during the difference code analysis phase to more comprehensively assess the impact scope of code changes; using precision testing technology to guide case library maintenance; generating incremental code coverage reports to evaluate testing quality for new requirements, etc.
5.2.1 Call Chain Analysis
During the difference code analysis phase, after parsing difference functions, a method call chain analysis step can be added. A method call chain refers to the process where one method calls another, forming a call chain. By analyzing method call chains, dependencies and execution order between methods can be traced, thereby better understanding code execution flow. Combined with method call chains, we can locate the upstream and downstream influence domains of difference methods, thereby more precisely identifying all affected methods, more comprehensively assessing the impact scope of code changes, and performing intelligent case recommendation accordingly.
Specifically, we can use static analysis techniques or dynamic analysis techniques to construct method call chains. Static analysis techniques can analyze code during compilation or before execution, primarily generating method call chains by parsing code structure and semantics. Static analysis is fast but can only obtain static call chain information, not supporting obtaining call chains generated at runtime such as dynamic proxies and reflection. Dynamic analysis refers to collecting and analyzing code execution information during program runtime, capturing method call chains by monitoring program execution flow and method calls. Dynamic analysis can obtain accurate runtime call chain information but may have certain performance impacts.
Currently, the industry primarily obtains method call chains through static analysis. In Java, bytecode manipulation frameworks can be used for static call chain analysis, such as ASM and Javassist. ASM provides low-level, fine-grained bytecode operation APIs, directly manipulating bytecode instructions, thus performing better in terms of performance; Javassist abstracts bytecode structure and instruction sets, providing easy-to-use APIs with low learning curves. In Java, Java Agent weaving can be used to obtain dynamic method call chains, but the impact on application performance requires careful evaluation and testing.
5.2.2 Test Case Library Maintenance
During the test case library maintenance process, the following indicators can be used to evaluate and manage the quality and effectiveness of test cases:
|
Indicator |
Purpose |
|---|---|
|
Code Coverage |
Measures the extent to which test cases cover code or functionality |
|
Recommendation Frequency |
Higher frequency indicates higher test case reusability and quality |
|
Defect Tracking |
Tracking the number and severity of defects associated with test cases helps evaluate whether cases can discover problems and provide sufficient information |
|
Case Pass Rate |
Recording case execution results (pass, fail, blocked, etc.) and pass rate (proportion of passed cases to total cases) helps evaluate case applicability and accuracy—cases with low pass rates may require further review and adjustment |
|
Case Priority |
Mainly evaluated manually based on business requirements |
5.2.3 Incremental Code Coverage Report
During the regression testing phase, execute recommended regression cases together with newly added cases for this iteration, collect incremental code coverage, and generate reports. Use incremental code coverage reports to determine the testing quality of this regression—whether it meets the code coverage metrics required for release. If indicators are not met, locate missing test code through incremental code coverage reports and add corresponding test cases.
5.2.4 Automated Recording Feasibility
Our company has currently recorded interface automation cases, and the next step will be to organize and record UI automation cases and some manual cases, enriching the case knowledge base. Additionally, consider integrating with the DevOps platform, optimizing semi-automated case recording operations to automated recording. Furthermore, during the code coverage parsing phase, establish a call chain knowledge base through method call chain analysis. When code changes cause call chain alterations, combined with the call chain knowledge base, we can identify which test cases have changed mapping relationships with covered functions, thereby triggering automated recording and parsing, achieving automatic updates of mapping relationships between test cases and covered functions.
VI. Conclusion
To improve testing efficiency and quality for our company's (Shenwanhongyuan Securities Co., Ltd.) fund projects, we introduced precision testing and successfully conducted application practice of the intelligent test case recommendation system. Through the intelligent test case recommendation system, we can obtain code change situations, precisely recommend regression test cases related to changes, and provide code difference reports and case recommendation reports to guide testers in testing. In the regression testing phase, precision recommendation achieves 15.91% case compression, reducing the required interface tests from 803 to 264 (32.88% of the original). We can more efficiently select representative and important test cases, maintaining test coverage while reducing redundant testing, effectively improving regression testing efficiency and quality.
In the future, based on the intelligent case recommendation system, we will conduct in-depth work on call chain analysis, test case library maintenance guidance, incremental code coverage analysis, and automated recording, further achieving quality and efficiency improvements in business testing.
0
Latest Posts
1Beyond "Sending Screenshots to LLMs": An Alternative Approach to Mobile UI Automation Traditional multimodal LLM UI automation faces high token costs, slow inference and black-box flaws. This structured parsing solution enables efficient, stable mobile UI automation with pure text LLM input.
2From Manual Testing to Full-Process AI Integration: How QA Teams Reimagine Their Organizations for the AGI Era Learn 5 actionable AGI transformation practices for quality teams, AI testing toolchain building & full-stack AI coding quality governance from enterprise real cases.
3Are Test Dev Engineers Still Relevant in the LLM Era? FDE Career Guide 2026 Explore surging demand for Forward Deployed Engineers (FDEs) in the LLM space. Learn how test development engineers can shift to enterprise AI delivery roles.
4Java Code Coverage: Principles and Enterprise CI/CD Best Practices Learn Java code coverage fundamentals, bytecode instrumentation modes, and enterprise CI/CD testing practices with JaCoCo and Cobertura for reliable software quality.
5Java Code Coverage: Principles, Instrumentation & CI/CD Best Practices Learn Java code coverage fundamentals, bytecode instrumentation with JaCoCo & Cobertura, and production-grade unit & integration testing CI/CD engineering practices.
Tools
UDT: Auto-Testing Platform
Customized Auto-Testing Platform
Real Device Cloud
PerfDog
CrashSight
PerfSight
Featured Services
APP Compatibility Testing
APP Functional Testing
Mobile Game Hardening
Penetration Testing
Crowd Testing
Localization Quality Assurance
Featured Solutions
Mobile Game Solutions
PC Game Solutions
Overseas Local User Testing Solutions
Mini Program Security Testing Solutions
ISO 9001:2015
Quality Management System Certification
ISO/IEC 20000-1:2018
IT Service Management System Certification
ISO/IEC 27001:2013
ISO/IEC 27001:2013
Copyright © 1998 - 2025 Top Range Mobile Limited.(WeTest.net) All Rights Reserved